MongoDB 基础教程
- MongoDB 教程
- MongoDB 简介
- MongoDB 优势
- MongoDB 环境安装
- MongoDB 数据建模
- MongoDB 创建数据库
- MongoDB 删除数据库
- MongoDB 创建集合
- MongoDB 删除集合
- MongoDB 数据类型
- MongoDB 插入文档
- MongoDB 查询文档
- MongoDB 更新文档
- MongoDB 删除文档
- MongoDB 文档投影
- MongoDB Limit 与 Skip方法
- MongoDB 记录排序
- MongoDB 索引
- MongoDB 聚合
- MongoDB 复制(副本集)
- MongoDB 分片
- MongoDB 创建备份
- MongoDB 部署
- MongoDB Java
- MongoDB PHP
MongoDB 高级教程
MongoDB 数据建模
MongoDB中的数据在同一集合中具有灵活的模式 schema.documents 。同一集合中的文档。它们不需要具有相同的字段集或集合中的结构公共字段,文档可能包含不同类型的数据。
数据模型设计
MongoDB提供两种类型的数据模型:嵌入式数据模型和规范化数据模型。根据需求,您可以在准备文档时使用这两个模型中的任何一个。
嵌入式数据模型
在此模型中,您可以将所有相关数据(嵌入)在一个文档中,这也称为非规范化数据模型。
例如,假设我们在三个不同的文档(Personal_details,Contact 和 Address)中获取员工的详细信息,则可以将所有三个文档嵌入到一个文档中,如下所示:
{
_id:,
Emp_ID: "10025AE336"
Personal_details:{
First_Name: "Radhika",
Last_Name: "Sharma",
Date_Of_Birth: "1995-09-26"
},
Contact: {
e-mail: "radhika_sharma.123@gmail.com",
phone: "9848022338"
},
Address: {
city: "Hyderabad",
Area: "Madapur",
State: "Telangana"
}
}标准化数据模型
在此模型中,您可以使用引用来引用原始文档中的子文档。例如,您可以将以下文档以规范化模型重写为:
Employee:
{
_id: <ObjectId101>,
Emp_ID: "10025AE336"
}Personal_details:
{
_id: <ObjectId102>,
empDocID: " ObjectId101",
First_Name: "Radhika",
Last_Name: "Sharma",
Date_Of_Birth: "1995-09-26"
}Contact:
{
_id: <ObjectId103>,
empDocID: " ObjectId101",
e-mail: "radhika_sharma.123@gmail.com",
phone: "9848022338"
}Address:
{
_id: <ObjectId104>,
empDocID: " ObjectId101",
city: "Hyderabad",
Area: "Madapur",
State: "Telangana"
}在MongoDB中设计架构时的注意事项
根据用户要求设计架构。
如果将它们一起使用,则将它们组合到一个文档中。否则,将它们分开(但请确保不需要连接)。
复制数据(但有限制),因为磁盘空间比计算时间便宜。
在写入时进行联接,而不是在读取时进行联接。
针对最常见的用例优化您的方案。
在架构中进行复杂的聚合。
在线示例
假设客户需要为其博客/网站进行数据库设计,并查看RDBMS与MongoDB模式设计之间的区别。网站具有以下要求。
每个帖子都有唯一的标题,描述和网址。
每个帖子可以有一个或多个标签。
每个帖子都有其发布者的姓名和点赞的总数。
每个帖子都有用户提供的评论,以及他们的姓名,消息,数据时间和点赞。
在每个帖子上,可以有零个或多个评论。
在RDBMS架构中,用于上述要求的设计将至少具有三个表。
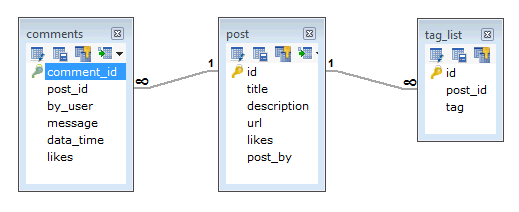
在MongoDB模式中,设计将具有一个帖子集合和以下结构-
{
_id: POST_ID
title: TITLE_OF_POST,
description: POST_DESCRIPTION,
by: POST_BY,
url: URL_OF_POST,
tags: [TAG1, TAG2, TAG3],
likes: TOTAL_LIKES,
comments: [
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
},
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
}
]
}因此,在显示数据时,在RDBMS中,您需要连接三个表,而在MongoDB中,数据将仅从一个集合中显示。